

Theme: Machine Learning: Discovering the New Era of Intelligence
Renowned Speakers
 Rohit Agarwal
Rohit AgarwalMobisy Technologies Pvt Ltd
India
 Santosh Godbole
Santosh GodboleSSN Solutions Limited
India
 Ahmed AlMaqabi
Ahmed AlMaqabiAlmaqabi
Bahrain
 Shabir Momin
Shabir MominZengaTV
Singapore
 Manoj Mishra
Manoj MishraUnion Insurance
United Arab Emirates
 Mahmoud Moussa
Mahmoud MoussaMicrosoft Corporation
United Arab Emirates
 Erwin E. Sniedzins
Erwin E. SniedzinsMount Knowledge Inc.
Canada
 Samir El-Masri
Samir El-MasriDigitalization.Cloud
UAE
 Sylvester Juwe
Sylvester Juwe British Gas
UK
 Niladri Shekhar Dutta
Niladri Shekhar DuttaEricsson
United Arab Emirates
 Tilila El Moujahid
Tilila El MoujahidMicrosoft
United Arab Emirates
 Jayatu Sen Chaudhury
Jayatu Sen ChaudhuryAmerican Express
India
 Eman AbuKhousa
Eman AbuKhousaUAE University
United Arab Emirates
 Anu Kukar
Anu KukarKPMG
Australia
 Najati Ali-Hasan
Najati Ali-HasanAnchor IT Consultation
United Arab Emirates
 Abbas M Al-Bakry
Abbas M Al-BakryUniversity of Information Technology and Communications
Iraq
 Kai Khalid Miethig
Kai Khalid MiethigTariq Faqeeh Engineering
Bahrain
 Abed Benaichouche
Abed BenaichoucheInception Institute of Artificial Intelligence
United Arab Emirates
 Balasubramanyam Pisupati
Balasubramanyam PisupatiRobert Bosch Engineering and Business Solutions Limited
India
 Noor Alasadi
Noor AlasadiDamascus University
Iraq
 Nabil Belgasmi
Nabil BelgasmiBanque de Tunisie
Tunisia
Machine Learning 2018

MEConferences team cordially invites all participants across the world to attend the 5th World Machine Learning and Deep Learning Congress (Machine Learning 2018) which is going to be held during January 28-29 in Abu Dhabi, UAE. The main theme of the conference is “Machine Learning: Discovering the New Era of Intelligence". This conference aimed to expand its coverage in the areas of Machine Learning and Deep Learning where expert talks, young researcher’s presentations will be placed in every session of the meeting will be inspired and keep up your enthusiasm. We feel our expert Organizing Committee is our major asset, however Speakers are what make events stand out. World Machine Learning and Deep Learning Congress is bringing the most innovative minds, practitioners, experts and thinkers to inspire and present to the delegates new innovative ways to work and innovate through their data. Your presence over the venue will add one more feather to the crown of Machine Learning 2018.
Machine Learning is a method of teaching computers how to perform complex tasks that cannot be easily described or processed by humans and to make predictions. It is a combination of Mathematical Optimization and Statics. In the other hand, Deep Learning is the subset of ML that focus even more narrowly like neuron level to solve any problem. Machine Learning 2018 is comprised of the following sessions with 20 tracks designed to offer comprehensive sessions that address current applications, discoveries, and issues of Machine Learning and Deep Learning.
The target audience for the conference:
- Data Engineers/Developers
- Startup Professionals
- Scientists/Researchers
- Professors
- President/Vice president
- Chairs/Directors
And last but not the least……….
- Anyone interested in Machine Learning & thrives to make the future developed and better
Highlights and Advancements in Artificial Intelligence, Machine Learning & Deep Learning
MEConferences team cordially invites all the participants from all over the world to attend World Machine Learning and Deep Learning Congress during August 30 - 31, 2018 in Dubai, UAE. This includes prompt keynote presentations, Oral talks, Poster presentations and Exhibitions.
Track: Machine Learning
Machine Learning is a subset of Artificial Intelligence (AI) that provides computers with the ability to learn without being explicitly programmed and to make intelligent decisions. It also enables machines to grow and improve with experiences. It has various applications in science, engineering, finance, healthcare and medicine.
Advantages of Machine Learning-
- Useful where large-scale data is available
- Large-scale deployments of Machine Learning beneficial in terms of improved speed and accuracy
- Understands non-linearity in the data and generates a function mapping input to output (Supervised Learning)
- Recommended for solving classification and regression problems
- Ensures better profiling of customers to understand their needs
- Helps serve customers better and reduce attrition
And many more………
This Machine Learning Conference is focused on adding more value & knowledge to the revolutionary era of Intelligence.
Track: Deep Learning
Deep Learning is a subset of Machine Learning which deals with deep neural networks. It is based on a set of algorithms that attempt to model high-level abstractions in data by using multiple processing layers, with complex structures or otherwise, composed of multiple non-linear transformations. Machine Learning Conferences has added the topic Deep Learning Conferences which will clear the doubts & will add more knowledge from the most innovative minds through out the globe.
Track: Artificial Intelligence
Artificial Intelligence is a technique which enables computers to mimic human behaviour. In other words, it is the area of computer science that emphasizes the creation of intelligent machines that work and reacts like humans. With increasing world of AI, knowledge transfer is also very much necessary. For that Machine Learning Conferences has added this very important topic of Artificial Intelligence meetup.
Types of Artificial Intelligence:
- Narrow Artificial Intelligence - Narrow artificial intelligence is also known as weak AI. It is an artificial intelligence that mainly focuses on one narrow task. Narrow AI is defined in contrast to either strong AI or artificial general intelligence. All currently existing systems consider artificial intelligence of any sort is weak AI at most. It is commonly used in sales predictions, weather forecasts & playing games. Computer vision & Natural Language Processing (NLP) is also a part of narrow AI. Google translation engine is a good example of narrow Artificial Intelligence
- Artificial General Intelligence
- Artificial Super Intelligence
Track: Internet of Things (IoT)
The Internet of things (IoT) refers to an umbrella that covers the entire network of physical devices, home appliances, vehicles and other items embedded with software, sensors, actuators, electronics and connectivity, or we can say with an IP address (Internet Protocol), which enables these objects to connect and exchange data, which resulting in enhanced efficiency, accuracy and economic advantage in addition to reduced human involvement.
Track: Artificial Neural Networks (ANN) & Chainer
A human brain has neurons that help in adaptability, learning ability & to solve any problem. Unlike Human brain, computer scientists dreamt for computers to solve the perceptual problems that fast. And hence, ANN model came into existence. Artificial Neural Networks is nothing but a biologically inspired computational model that consists of processing elements (neurons) and connections between them, as well as of training and recall algorithms. Artificial Neural Networks (ANN) Conference will help to build relation with the most eminent persons in the field.
Track: Deep Learning Frameworks
Deep Learning is a subset of Machine Learning which deals with deep neural networks. It is based on a set of algorithms that attempt to model high-level abstractions in data by using multiple processing layers, with complex structures or otherwise, composed of multiple non-linear transformations. Deep Learning is able to solve more complex problems and perform greater tasks. Deep Learning Framework is an essential supporting fundamental structure that helps to make complexity of DL little bit easier.
Track: The Role of AI & Machine Learning in Medical Science
Machine learning works effectively in the presence of huge data. Medical science is yielding large amount of data daily from research and development (R&D), physicians and clinics, patients, caregivers etc. These data can be used for synchronizing the information and using it to improve healthcare infrastructure and treatments. This has potential to help so many people, to save lives and money. As per a research, big data and machine learning in pharma and medicine could generate a value of up to $100B annually, based on better decision-making, optimized innovation, improved efficiency of research/clinical trials, and new tool creation for physicians, consumers, insurers and regulators. Due to the presence of enormous data in Healthcare, Machine Learning Conferences are adding medical Science topic in their every meetup.
Track: Natural Language Processing (NLP) and Speech Recognition
Natural Language Processing (NLP) is a sub-set of artificial intelligence that focuses on system development that allows computers to communicate with people using everyday language. Natural language generation system converts information from computer database into readable human language and vice versa.
The field of NLP is divided in 2 categories:-
- Natural Language Understanding (NLU)
- Natural Language Generation (NLG)
Track: Computer Vision and Image Processing
Computer Vision is a sub-branch of Artificial Intelligence whose goal is to give computers the powerful facility for understanding their surrounding by seeing the things more than hearing or feeling, just like humans. It is used for processing, analyzing and understanding digital images to extract information from that. In other words, it transforms the visual images into description of the words. Machine Learning Conference gives a platform for the researchers to come & talk on a common platform.
Track: Pattern Recognition
Pattern Recognition is a classification of Machine Discovering that predominantly concentrates on the acknowledgement of the structure and regularities in detail; however, it is considered almost similar to machine learning. Pattern Recognition has its cause from engineering, and the term is known with regards to Computer vision. Pattern Recognition, for the most part, has a better enthusiasm to formalize, illuminate and picture the pattern and give the last outcome, while machine learning customarily concentrates on expanding the recognition rates before giving the last yield. Pattern Recognition algorithms normally mean to give a reasonable response to every single input and to perform in all probability coordinating of the data sources, taking into charge their statistical variety. There are various uses of Pattern Recognition.
Track: Facial Expression and Emotion Detection
The use of machines in the public has expanded widely in the most recent decades. These days, machines are utilized as a part of a wide range of businesses. As their introduction with people increment, the communication additionally needs to wind up smoother and more characteristic. Keeping in mind the end goal to accomplish this, machines must be given an ability that let them get it the encompassing condition. Exceptionally, the intentions of a person. At the point when machines are eluded, this term includes to computers and robots. Deep Learning conference will talk in depth about facial expression & emotion detection.
Track: Predictive Analytics
Predictive Analytics is the branch of advanced analytics which offers a clear view of the present and deeper insight into the future. It uses different techniques and algorithms from statistics and data mining, to analyze current and historical data to predict the outcome of future events and interactions. Big Data Conference, Artificial Intelligence Conference as well as Machine Learning summit keep Predictive Analytics as its main part because of its vast scope.
Track: Big Data, Data Science and Data Mining
Nowadays, a huge quantity of data is being produced daily. Machine Learning uses those data and provides a noticeable output that can add value to the organization and will help to increase ROI,
Big Data is informational indexes that are so voluminous and complex that conventional data handling application programming is lacking to manage them. Big Data challenges incorporate capturing data, data storage, data analysis, search, sharing, transfer, visualization, querying, and updating and data security. There are three dimensions to Big Data known as Volume, Variety and Velocity.
Data Science manages both structured and unstructured data. It is a field that incorporates everything that is related to the purging, readiness and last investigation of data. Data science consolidates the programming, coherent thinking, arithmetic and statistics. It catches information in the keenest ways and supports the capacity of taking a gander at things with an alternate point of view.
Data mining is essentially the way toward collecting information from gigantic databases that was already immeasurable and obscure and after that utilizing that information to settle on applicable business choices. To put it all the more essential, Data mining is an arrangement of different techniques that are utilized as a part of the procedure of learning disclosure for recognizing the connections and examples that were beforehand obscure. We can thusly term data mining as a juncture of different fields like artificial intelligence, data room virtual base management, pattern recognition, visualization of data, machine learning, and statistical studies and so on.
Track: Big Data Analytics
Big Data Analytics gives a handful of usable data after examining hidden patterns, correlations and other insights from a large amount of data. That as a result, leads to smarter business moves, higher profits, more efficient operations and finally happy customers. And Big Data Conference adds more value to it.
Big Data Analytics adds value to the organization in following ways:
- Cost reduction
- Faster, Better decision making
- New Products and Services
Track: Dimensionality Reduction
In Machine Learning, when machine captures data, they find random data. Then machine learning uses dimensionality reduction or dimension reduction is the process for reducing the number of random variables under consideration by obtaining a set of principal variables. It can be divided into feature selection and feature extraction.
Track: Model Selection and Boosting
Model Selection is the undertaking of choosing a statistical model from an arrangement of candidate models, given information. In the least difficult cases, a prior arrangement of information is considered. However, the assignment can likewise include the outline of trials with the end goal that the information gathered is appropriate to the problem of model selection. Given candidate models of comparable prescient or illustrative power, the least complex model is well on the way to be the best decision
Boosting is a machine learning ensemble meta-algorithm for essentially lessening inclination, and furthermore changes in supervised learning, and a group of machine learning algorithms which change over weak learners to strong ones. A weak learner is characterized to be a classifier which is just marginally related to the genuine characterization (it can name cases superior to anything irregular speculating). Conversely, a strong learner is a classifier that is subjectively all around connected with the genuine classification. It plays a very important role in Machine Learning Conference.
Track: Object Detection with Digits
Object detection with digits is a piece of Deep Learning. It is a standout amongst the most difficult issues in computer vision and is the initial phase in a several computer vision applications. The objective of an object detection system is to recognize all examples of objects of a known classification in a picture. Because of its important existence, Deep Learning Conferences always include a track on Object Detection with Digits.
Track: Cloud Computing
Cloud Computing is a delivery model of computing services over the internet. It enables real-time development, deployment and delivery of broad range of products, services and solutions. It is built around a series of hardware and software that can be remotely accessed through any web browser. Generally, documents and programming are shared and dealt with by numerous clients and all information is remotely brought together as opposed to being put away on clients' hard drives. Machine Learning Conferences has included a special talk on Clod Computing.
Track: Robotic Process Automation (RPA)
Robotic Automation lets organizations automate current tasks as if a real person was doing them across applications and systems. RPA is a cost cutter and a quality accelerator. Therefore RPA will directly impact OPEX and customer experience, and benefit to the whole organization and this is why it becomes a main topic to be discussed in Machine Learning Conference.
World Machine Learning and Deep Learning Congress welcome presenters, exhibitors and attendees to Dubai, UAE during August 30-31, 2018. The organizing committee is preparing for an exciting and informative conference program including lectures, workshops, symposia on a wide variety of topics, poster presentations and various programs for participants from across the world. We invite you to join us at the Machine Learning 2018, where you will be sure to have a meaningful experience with scholars from around the globe. All members of the Machine Learning 2018 organizing committee look forward to meeting you in Dubai, UAE.
Scope and importance:
Previously Machine Learning & Deep Learning was used to construct software from training examples. Its method was also extended to support data mining and knowledge discoveries. Then ML & DL started doing perceptual tasks like deep learning for computer vision, speech recognition etc. After that its main work was automated decision making & anomaly detection (Cyber Security, Fraud Detection and Machine Diagnosis). But the Future of ML & DL is beyond imagination and it can control & work on variety of topics like:
- Detecting and Correcting for Bias
- Risk Sensitive Optimization
- Explanations of Black Box Systems
- Verification and Validation
- Integrating ML Components into Larger Software Systems
The market of Machine Learning & Deep Learning is growing exponentially worldwide. According to the research, the global machine learning market is expected to grow from $ 1.41 Billion in 2017 to $ 8.81 Billion by 2022, at a Compound Annual Growth Rate (CAGR) of 44.1% and the Global Machine Learning as Service market is expected to grow from $ 480.94 million in 2015 to reach $ 5,394.87 million by 2022 with a CAGR of 41.2%.
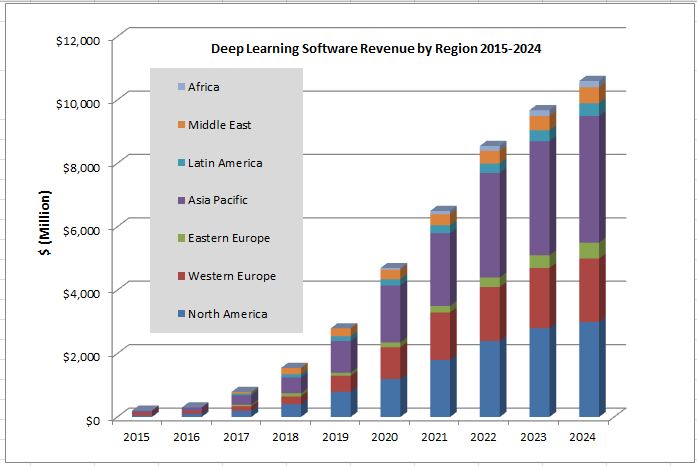
Machine learning enabled solutions are being significantly adopted by organizations worldwide to enhance customer experience, Return on Investment (ROI), and to gain a competitive edge in business operations. Moreover, in the coming years, applications of machine learning in various industry verticals are expected to rise exponentially. Some of the verticals are:
- BFSI
o Applications of machine learning in BFSI
- Fraud and Risk Management
- Investment Prediction
- Sales and Marketing Campaign Management
- Customer Segmentation
- Digital Assistance
- Others (compliance management and credit underwriting)
- Healthcare and Life Sciences
o Applications of machine learning in healthcare and life sciences
- Disease Identification and Diagnosis
- Image Analytics
- Drug Discovery/Manufacturing
- Personalized Treatment
- Others (clinical trial research and epidemic outbreak prediction)
- Retail
o Applications of machine learning in retail
- Inventory Planning
- Upsell and Cross Channel Marketing
- Segmentation and Targeting
- Recommendation engines
- Others (customer ROI and lifetime value, and customization management)
- Telecommunication
o Applications of machine learning in telecommunication
- Customer Analytics
- Network Optimization
- Network Security
- Others (digital assistance/contact centres analytics and marketing campaign analytics)
- Government and Defence
o Applications of machine learning in government and defence
- Threat Intelligence
- Autonomous Defence system
- Others (sustainability and operational analytics)
- Manufacturing
o Applications of machine learning in manufacturing
- Predictive Maintenance
- Demand Forecasting
- Revenue Estimation
- Supply Chain Management
- Others (root cause analysis and telematics)
- Energy and Utilities
o Applications of machine learning in energy and utilities
- Power/Energy Usage Analytics
- Seismic Data Processing
- Smart Grid Management
- Carbon Emission
- Others (customer specific pricing and renewable energy management)
- Others (Education, Agriculture, Media and Entertainment, and Education)
Why Dubai, UAE:
UAE is the city of world’s best architecture and now it is stepping towards the advanced future of Artificial Intelligence. UAE believes in Smart Smarter Smartest… and therefore the government took AI adoption one step further by installing a minister in-charge of AI.
Few actions of UAE Government in the field of AI and Machine Learning in past years are:
- 2000 – E-Government-the first government to move to e-government system
- 2013 – Smart Government-launched services to public wherever they are round the clock
- 2015 – Smart Transformation – Achieved 100% e-government transformation
- 2017 – Artificial Intelligence-launched AI strategy as part of UAE Centennial 2071
Why to Attend???
ML conference gathers communities to discuss the recent research and application of Algorithms, Tools, and Platforms to solve the hard problems that exist within organizing and analyzing massive and noisy data sets. Machine Learning 2018 invites attendees from around the world focused on learning about ML & DL. This would be one of best opportunity to reach the largest assemblage of participants from the ML community. Conduct demonstrations, distribute information, meet with current and potential customers, make a splash with a new product line, and receive name recognition at this 2-day event. World’s renowned speakers, the most recent techniques, highlights, discoveries and the newest updates in ML & DL fields are hallmarks of this conference.
- Extraordinary speakers
Discover advances in ML and DL algorithms and methods from the world's leading speakers, researchers and scholars. Learn from industry experts in speech & pattern recognition, neural networks, image analysis and NLP. Explore how Machine Learning and Deep Learning will impact finance, healthcare, manufacturing, search & transportation.
- Discover emerging trends
The congress will showcase the opportunities of advancing trends in Machine Learning & Deep Learning and their impact along with successful applications in business. It will also focus on the challenges and areas of improvement related to the field of research and applications. Learn the latest technological advancements & industry trends from a global line-up of experts.
- Expand your network
A unique opportunity to connect with industry leaders, influential technologists, Machine Learning Professionals & founders leading the deep learning revolution. Learn from & interact with various industry innovators sharing best practices to advance the smart artificial intelligence revolution and become a part of it.
Industries Associated with Machine Learning:
World Wide:
- GOOGLE – For developing a photographic memory
- IBM – For embedding Watson where it’s needed most
- BAIDU – For accelerating mobile search with artificial intelligence
- SOUNDHOUND – For giving digital services the power of human speech
- ZEBRA MEDICAL VISION – For using deep learning to predict and prevent diseases
- PRISMA - For making masterpieces out of snapshots
- IRIS AI - For speeding up scientific research by surfacing relevant data
- PINTEREST - For serving up a universe of relevant pins to each and every user
- TRADEMARKVISION - For helping start-ups make their mark without any legal confusion
- DESCARTES LABS - For preventing food shortages by predicting crop yields
- APPLE
- AMAZON
Universities Associated with Machine Learning:
World Wide:
- Carnegie Mellon University
- University of Michigan Ann Arbor
- Cornell
- Berkeley
- Stanford
- Columbia University
- University of Washington
- Georgia Tech
- University of California San Diego
- University of Massachusetts Amherst
- John Hopkins University
- University of Illinois Urbana Champaign
- Penn State University
- University of North Carolina Chapel Hill
- California Institute of Technology
- University of Wisconsin Madison
Major Societies & Groups Worldwide-
- The International Machine Learning Society (IMLS)
- American Statistical Association
- IEEE Computer Society
- European Knowledge Discovery Network of Excellence (KDNet)
- National Centre for Data Mining (NCDM)
- Pacific Rim International Conferences on Artificial Intelligence
- Canadian Artificial Intelligence Association
- The European Coordinating Committee on AI (ECCAI)
- Special Interest Group on Artificial Intelligence, Computer Society of India
- Japanese Society of Artificial Intelligence
- Sociedad Mexicana de Inteligencia Artificial
- Russian Association for Artificial Intelligence
- Computing Research Association
- The Society for the Study of Artificial Intelligence AND Simulation of Behaviour
- The International Neural Network Society
Related Societies:
USA: ML Society; The International Machine Learning Society; The Association For The Advancement Of Artificial Intelligence; The Artificial Intelligence Society; AI & Society; The Association for Uncertainty in Artificial Intelligence; Society for Artificial Intelligence; Conference on Uncertainty in Artificial Intelligence; Artificial Intelligence International; Slovenian Pattern Recognition Society; International Association of Computer Science and Information Technology; Global Cleantech Cluster Association; Czechoslovak Pattern Recognition Society; Bulgarian Association for Pattern Recognition; The Swiss Association for Pattern Recognition; The British Machine Vision Association and Society for Pattern Recognition;
Europe: European Association for Artificial Intelligence; Conexus Deep Learning Society; Deep Learning Society – Atlantic Rim Collaboratory; the Hellenic Artificial Intelligence Society; the European Coordinating Committee for Artificial Intelligence; Artificial Intelligence International; The Association for Uncertainty in Artificial Intelligence; Special Interest Group of the Brazilian Computer Society; French Association for Pattern Recognition and Interpretation; National Committee of the Russian Academy of Sciences for Pattern Recognition and Image Analysis; Mexican Association for Computer Vision, Neurocomputing and Robotics, Nederlandse Vereniging voor Patroonherkenning en Beeldverwerking; Italian Association for Pattern Recognition
Asia Pacific & Middle East: Indian Unit for Pattern Recognition and Artificial Intelligence; Artificial Intelligence Society of Hong Kong; Pattern Recognition and Machine Intelligence Committee of the Chinese Association of Automation; Artificial Intelligence Association of India; The Society for the Study of Artificial Intelligence and Simulation of Behaviour; Australian Pattern Recognition Society; Hong Kong Society for Multimedia and Image Computing; Pattern Recognition and Machine Intelligence Committee of the Chinese Association of Automation; The Macau Society for Pattern Recognition and Image Processing; Pakistani Pattern Recognition Society (PRRS); Computer Vision and Pattern Recognition Group of The Korean Institute of Information Scientists and Engineers
Related Conferences:
- 6th Convention on Robots and Deep Learning, September 10-11, 2018, Singapore
- 16th Deep Learning Summit, January 25-26, 2018, San Francisco
- Deep Learning Summit, September 20-21, 2018, London
- Artificial Intelligence Conference, January 17-19, 2018, Santa Clara, CA, USA
- Deep Learning for Enterprise Summit, January 25-26, 2018, San Francisco, CA, USA
- AI Assistant Summit, January 25-26, 2018, San Francisco, USA
- Deep Learning in Finance Summit, March 15-16, 2018, London, UK
- Deep Learning in Retail and Advertising Summit, March 15-16, 2018, London, UK
- The AI Conference Beijing (O'Reilly), April 10-13, 2018, Beijing, China
- Machine Intelligence Summit, April 12-13, 2018, Hong Kong
- Deep Learning Summit, April 12-13, 2018, Hong Kong
- Deep Learning in Healthcare Summit, May 24-25, 2018, Boston, USA
- AI in Industrial Automation Summit, June 21-22, 2018, San Francisco, USA
- Deep Learning for Robotics Summit, June 21-22, 2018, San Francisco, USA
- 14th Conference on Machine Learning and Data Mining, July 14-19, 2018, New York, USA
- Applied AI Summit, July 9-11, 2018, London, UK
- Congress on Computer science, Machine Learning and Big data analytics August 30-31, 2018, Dubai UAE
- Summit on Artificial Intelligence and Neural Network, October 15-16, 2018, Helsinki, Finland
- 7th Conference on Artificial Neural Networks, October 05-07, 2018 Rhodes, Greece
- 5th conference on Artificial Intelligence, April 16-17, 2018, Las Vegas; USA
- Conference on Artificial Intelligence, Robotics & IoT, August 21-22, 2018, Paris, France
- Joint Conference on Neural Networks, July 08-13, 2018, Rio de Janeiro, Brazil
- Conference on Artificial Neural Networks, November 21-23, 2018, Kuala Lumpur, Malaysia
- 27th Conference on Artificial Neural Networks, October 05-07, 2018, Rhodes, Greece
- 4th Summit and Expo on Multimedia & Artificial Intelligence, July 19-21, 2018, Rome, Italy
What will you learn???
Knowledge is everywhere; you can learn whatever you want from any source. But Machine Learning 2018 has made your search easy & compiled 19 sessions on emerging topics at a single place. Those sessions are:
- Machine Learning
- Deep Learning
- Artificial Intelligence
- Artificial Neural Networks (ANN) & Chainer
- Deep Learning Frameworks
- TensorFlow
- The role of AI & Machine Learning in Medical Science
- Natural Language Processing (NLP) and Speech Recognition
- Computer Vision and Image Processing
- Pattern Recognition
- Facial Expression and Emotion Detection
- Predictive Analytics
- Big Data, Data Science and Data Mining
- Big Data Analytics
- Dimensionality Reduction
- Model Selection and Boosting
- Object Detection with Digits
- Cloud Computing
- Robotic Process Automation (RPA)
We feel our expert Organizing Committee is our major asset, however, Speakers are what make events stand out. World Machine Learning and Deep Learning Congress is bringing most innovative minds, practitioners, experts, thinkers, eminent Researchers, Scientists, Professors, Developers, Analysts and Newbies under a solitary rooftop to inspire and present to the delegates new innovative ways to work and innovate through their data. Your presence over the venue will add one more feather to the crown of Machine Learning 2018.
Automation and Robotics 2017 Report
Thanks to all our wonderful speakers, conference attendees, Automation and Robotics-2016 Conference was the best!
The 2nd World Congress on Automation and Robotics, hosted by the MEConferences was held during June 13-15, 2016 at DoubleTree by Hilton Philadelphia Airport, Philadelphia, USA with the theme “Automation and Robotics for a Sustainable Future". Benevolent response and active participation was received from the Editorial Board Members of OMICS Group Journals as well as from the scientists, engineers, researchers, students and leaders from the fields of Automation and Robotics, who made this event successful.
The meeting was carried out through various sessions, in which the discussions were held on the following major scientific tracks:
- Industrial Automation
- Automation Tools and Technologies
- Control and Mechatronic Systems
- Robotics and Applications
- Manufacturing Automation
- Internet of Things
- Process and Energy Automation
- Security in Manufacturing Industries
- Automation systems
- Automation solutions
The conference was initiated with a series of lectures delivered by both Honorable Guestsand members of the Keynote forum. The list included:
Eduard Babulak, The Institute of Technology and Business in Ceske Budejovice, Czech Republic
Farrokh Janabi Sharifi, Ryerson University, Canada
Petter Falkman, Chalmers University of Technology Sweden
James P Gunderson, GunderFish LLC, USA
Asim ur Rehman Khan, National University of Computer & Emerging Sciences, Pakistan
Jerry Vinther, Lillebaelt Academy University of Applied Sciences, Denmark
MEConferences offers its heartfelt appreciation to the Organizing Committee Members, adepts of field, various outside experts, company representatives and other eminent personalities who supported the conference by facilitating the discussion forums. MEConferences also took privilege to felicitate the Organizing Committee Members and Editorial Board Members who supported this event.
MEConferences is proud to announce the "5th World Machine Learning & Deep Learning Congress" to be held during August 30-31, 2018 Dubai, UAE.
For More details visit: https://machinelearning.conferenceseries.com/
Emerging Trends in AI, Machine Learning & Deep Learning
Types of Datasets in Machine Learning
They are mainly three different types of datasets in Machine Learning. They are as follows:
- Training,
- Testing,
- Validation.
As we know previously, Machine Learning is all about building mathematical models as a way to understand information. The major learning aspect enters the process when the machine learning has a capability of adjusting its internal parameters. We will tweak those parameters so that the version explains the facts better. In a sense, this will be understood as the version of machine learning from the data. Once the model has learned enough then we can ask it to give an explanation for newly determined statistics.
Training Data Set:
A model is initially fit on a training dataset if it is a fixed example of the parameters of that model. The model is then skilled at the training dataset with the usage of a supervised mastering technique. In practice, the training dataset frequently encompasses a pair of an enter vector and the corresponding answer vector or scalar, which is typically denoted as the target. The contemporary model will run with the training dataset and produces an end result, which is then compared with the target, for every enter vector inside the training dataset. It is primarily based on the end result of the contrast and the particular mastering set of rules being used, the parameters of the model are adjusted. The model fitting can include each variable selection and parameter estimation.
Testing Data Set:
A testing at dataset is a dataset that is unbiased of the training dataset, however, that follows the same possibility of distribution as the training dataset. If a model is fit to the training dataset then it also suits the test dataset as well. A better fitting of the training dataset as opposed to the testing dataset.A test set is, therefore an example used for the best to evaluate the performance (i.e. generalization). Once a model is trained on a training set, it is generally evaluated on a data set. Probably, these units are taken from the identical dataset, although the training set needs to be classified or enriched to increase an algorithm’s accuracy.
In the case of a trained network, the error can be computed by computing the sum of squares mistakes among the output and the target. We should not use the equal information for training as well as for testing. As it doesn’t allow us to know how properly the network generalizes and whether the overfitting has passed off or not. Therefore, we have to maintain separate pair in reserve for test set (input target) which aren't used for training purpose. This sort of information set is called as Testing Dataset.
Validation Set:
Successively, the fitted model is used to predict the responses for the observations in a third dataset called the validation dataset.Things get more complicated when we check how well the network is learning during training so that when to stop can be decided. As per we cannot use training data as well as the testing data because the training data set is overfitting, and the testing data set is for the final test.Thus, the third data set is called as the validation set and it is required to validate the learning so far. In statistics and it is known as cross-validation.
MACHINE LEARNING
Machine Learning is being a running heritage for years, powering cell packages and search engines like google. But currently, it has come to be a broadly circulated buzzword, with clearly all the latest technological improvements regarding some things of machine learning. An impressive upward thrust in facts and computing capabilities has made this exponential progress possible.
The splendid increase in sophistication and programs of gadget studying will define the technological trends of 2017. Their consequences will rely upon whether or not the utility provides fee and advantages to society as an entire and whether it has the capacity to clear up actual world troubles.
Machine learning (ML) and Artificial intelligence (AI) are advanced because of the ubiquity and speed of the hardware. There are pivotal matters occurring, but the last in truly captivating essential advances is Latent Dirichlet Allocation. Current advances were very mechanical, with the aid of the maximum exciting component now in ML is adverse than AI, in which people are showing that ML structures are at risk of statistics that they are able to count on and don’t apprehend because ML structures don’t apprehend something, and in case you know how a model was built, you can determine it. But, AI isn’t new; it’s the same problem and technique (to a point) that can explore community unrolling 20+ years ago to recognize neural networks, it’s just that we will not do even minimal unrolling anymore, so it’s easier to show flaws via demonstration, but not derivation.
The big data revolution is a way to transform how we live, work, and assume with the aid of process optimization, empowering perception discovery and enhancing selection making. The theme of this grand capacity is based on the ability to extract the value from such huge data via statistics analytics; gadget mastering it is at its center because of its potential to analyze the information and offer records pushed insights, selections, and predictions. However, traditional gadget learning strategies were evolved in an exceptional generation, and they are based totally upon a couple of assumptions, consisting of the information set becoming absolutely into memory, these broken assumptions, together with the massive statistics traits, are growing obstacles for the conventional techniques. Therefore, this compile summarizes and organizes machine learning challenges with data information. In comparison to different studies that discuss challenges, this work highlights the cause-effect courting with the aid of organizing challenges in line with Big Data Vs or dimensions that instigated the difficulty: quantity, speed, variety, or veracity. Furthermore, emerging system mastering methods and strategies are discussed in phrases of the way they may be capable of dealing with the numerous challenges with the final objective of helping practitioners pick out appropriate solutions for his or her use cases. Ultimately, a matrix relating the challenges and strategies is presented through the Big Data Analytics
DATA MINING
The Data mining is the system of discovering patterns in a massive information sets related to techniques at the intersection of gadget learning, information, and database systems. It is a process utilized by businesses to turn uncooked records into beneficial information. By the usage of software to search for patterns in big batches of records, and businesses can examinethem approximately by their customers and broaden more effective advertising techniques in addition to boom income and reduce the charges. Data mining depends on effective records of series andwarehousing in addition to computer processing. This is related to the algorithmsfor locating styles in big information sets. It is a necessary part of a contemporary enterprise, wherein data from its operations and clients are mined for gaining commercial enterprise perception. It is also vital in contemporary clinical endeavors. This is an interdisciplinary topic related to, databases, gadget getting to know the algorithms.
The actual data mining challenge is the semi-automatic or computerized evaluation of large portions of records to extract previously unknown, interesting patterns which include companies of statistics data (cluster evaluation), unusual facts (anomaly detection), and dependencies (association rule mining, sequential sample mining).
The Data mining can be misused and may then produce consequences which appear to be significant. However, which are not in reality but can be expected in future conduct and cannot reproduce a new pattern of information and endure little use.
It is the exercise of automatically looking big stores of facts to find out styles and tendencies that cross past simple analysis. This makes use of state-of-the-art mathematical algorithms to segment the statistics and compare the opportunity of future occasions. Data mining is also referred to as Knowledge Discovery in Data(KDD).
Machine learning Algorithms
They are different kinds of Machine Learning Algorithms that classified based upon their purpose some of them are discussed below:
· Supervised learning
· Unsupervised Learning
· Semi-supervised Learning
· Reinforcement Learning
Supervised Learning
- The supervised learning is the concept of characteristic approximation, where essentially, we make an algorithm and at the end of the method we choose the feature that best describes the enter data. Maximum of the time we aren't able to figure out the proper character that constantly makes the best predictions and other motive is that the set of rules depend on an assumption made through people about how the computer must research, and this assumption introduces a bias.
- Supervised learning algorithms try to model relationships and dependencies among the target prediction output and the input features such that we expect the output values for new facts primarily based on the relationships which it can find from the previous statistics units.
Unsupervised Learning
- The computer is being trained with unlabeled statistics. In reality, the computer is being capable of teaching you knew things after it learns the patterns in statistics, these algorithms are especially useful in instances where the human professional doesn’t know what to search for internal records.
- The machine learning algorithms are particularly used in sample detection and descriptive modeling. but, they are no output categories or labels here based on which the set of rules can try and model relationships. In the unsupervised algorithm, they try to use strategies on the input facts to mine for rules, locate styles and summarize and the organization information points out the meaningful insights and describes the information better to the customers.
Semi-supervised Learning
- As discussed above two types, either there are no labels for all the remark in the dataset or labels, but they are present for all of the observations. Semi-supervised learning falls among these. In many sensible situations, the cost to label is pretty excessive, because it calls for skilled human experts to try this. So, even though the absence of labels in the public of the observations however found in few, semi-supervised algorithms are the pleasant applicants for the model constructing. Those methods make the idea that the fact in the organization memberships of the unlabeled information is unknown, this statistic incorporates and are important about the group parameters
Reinforcement Learning
- This technique targets at using observations accumulated from the interplay with the surroundings to take actions that could maximize the reward or decrease the hazard. Reinforcement learning algorithm (called the agent) continuously learns from the environment in an iterative style. Within the procedure, the agent learns from its studies of the environment until it explores the full range of possible states.
- Reinforcement learning is a form of device mastering, and thereby also a department of Artificial Intelligence. It lets in machines and software retailers to automatically determine the correct conduct inside a context, to be able to maximize its performance. Simple reward feedback is needed for the agent to examine its conduct; that is referred to as the reinforcement sign
How Machine Learning is used in Diagnosis ?
Identification of diseases and analyzing the ailments is at the forefront of ML research in medicine. According to the research report of 2015 issued by Pharmaceutical researchers and manufactures of the United States, more than 800 medicines and vaccines to treat cancer were on trial. It additionally offers the project of finding methods to work with all the ensuing records. “This is in which the idea of a biologist running with information scientists and computation lists is so critical.”
It’s no surprise that large players were some of the first to jump on the bandwagon, most probably high-need areas like cancer identification and treatment. In October 2016, IBM Watson health announced IBM Watson Genomics, a partnership initiative with Quest Diagnostics, whose main idea was to make strides in precision remedy through integrating cognitive computing and genomic tumor sequencing.
Boston-primarily based biopharma company Berg is the use of AI to research and expand diagnostics and healing treatments in more than one areas, which include oncology. The current research initiatives underway include dosage trials for intravenous tumor remedy and detection and control of prostate cancer.
In the region of brain-primarily based diseases like despair, Oxford’s P1vital Predicting reaction to depression treatment (predict). This mission is the used for predictive analytics to help diagnose and offer treatment, with the overall purpose of producing a commercially-available emotional test a battery for the use in scientific settings. Machine Learning offers a principled technique for growing state-of-the-art, automatic, and goal algorithms For the evaluation of excessive-dimensional and multimodal biomedical statistics. This evaluation specializes in numerous advances within the state of the artwork which have shown an improving detection, prognosis, and healing monitoring of sickness. Key to the development has been the development of information and theoretical evaluation of crucial issues associated withalgorithmic construction and learning theory. Those consist of alternate-offs for maximizing generalization overall performance, use of bodily sensible constraints, and incorporation of prior know-how and uncertainty. The evaluation describes latest traits in gadget mastering, focusing on supervised and unsupervised linear techniques and Bayesian inference, which have made great impacts in the detection and analysis of sickness in biomedicine. We describe the unique methodologies.
Some of the other major examples include Google’s DeepMind Health, which was announced last year by UK-based partnerships, including with Moorfield’s Eye Hospital in London, in which they were developing technology to address macular degeneration in aging eyes.
Internet of Things (IoT)
The internet of things (IoT) is defined as the concept that describes the of regular physical bodies that are being connected to the internet and being able to perceive themselves to different devices like cars, home appliances and other items embedded with electronics, software, sensors, actuators, and connectivity which allows these gadgets to connect and trade information.
In IoT, everything is uniquely identifiable via the embedded system however it may inter-function with the present infrastructure. This is especially the concept of essentially connecting any tool with an on and off switch to the internet. This majorly includes cell phones, washing machines, headphones, lamps, wearable devices.
IoT additionally includes other sensor technology, wireless technologies or QR codes. IoT encompasses the entirety linked to the net however, it is being used to outline items that "talk" to each other. The internet of things is made from gadgets – from easy sensors to smartphones and wearables
IoT is an essential driver for customer-facing innovation, data-driven optimization and automation, digital transformation and entirely new applications, business models and revenue streams across all sectors. An IoT business guide with the origins, technologies, and evolutions of IoT with business examples, applications and research across industries and several use cases.
IoT is an important driver for client-dealing with innovation, data-driven optimization and automation, virtual transformation and completely new packages, commercial enterprise fashions and revenue streams throughout all sectors. An IoT enterprise manual will guide with the origins, technologies, and evolutions of IoT.
MACHINE LEARNING IN PLANT BREEDING
With the aid of machine learning, plant breeding is becoming more accurate, efficient, and capable of evaluating a much wider set of variables. Researchers in modern agriculture are testing their theories at greater scale and helping make more accurate, real-time predictions. The digital testing does not replace the physical field trials but allows plant breeders to more accurately predict the performance of crops. Such advancements offer the potential to create even more adaptable, and productive seeds to better utilize our precious natural resources. In case a new variety reaches the soil, machine learning helps the breeders to create a vetted product.
The main objective of the modern agriculture is to create seeds and crop protection products that provide relief to the global challenges. Machine learning in agriculture allows more accurate disease diagnosis it helps in eliminating waste energy and resources from misdiagnoses. As we know most of the scientists are using the new technologies in Machine Learning to evaluate how a variety of crops are grown in different sub-climates, soil types, weather patterns, and other factors.
Crop disease is the major cause of famine and food insecurity around the world. One of the many benefits of machine learning is how this technology can make more accurate and precise improvements to a process. The machine learning is playing a major role to develop more efficient seeds in plant breeding.
The Modern agriculture has the potential to discover more relevant ways on how to conserve water, and how to use nutrients and energy more efficiently, and adapt to climate change. The most innovative way of machine learning in farming was the farmers can upload field images taken by satellites, land-based rovers, pictures from smartphones, and they used this software to diagnose and develop a management plan.
AI in Agriculture Market
The global artificial intelligence in agriculture market is segmented into technology, offering application, and region. Based on technology, the global AIA market is further divided into machine learning, computer vision, and predictive analytics. An Artificial Intelligence (AI) is a creation of intelligent machines that work and react & respond like humans. It is employed to improve the efficiency of daily tasks. Moreover, remote sensing techniques are also used to survey the quality and crop producing ability of an agricultural land.
The AIA market is segmented into hardware and software. The AIA market is segmented into North America, Europe, Asia-Pacific and almost all over the world. North America is expected to hold the major market share in the global AIA market during the last decade. The AIA market has many applications inprecision farming, livestock monitoring, drone analytics, agriculture robots. Based on application, the market is sub-divided as Agriculture Robots, Precision Farming, Livestock Monitoring, and Drone Analytics.
Machine learning development is the most important proportion owing to the growing adoption of the generation for numerous applications which encompass drone analytics, cattle rearing. However, Asia-Pacific is predicted to be the fastest developing market. The elements riding the growth of the Asia-Pacific market are speedy development information garage capability, high computing energy, and parallel processing.
Demystifying How Neural Networks involve in Deep Learning Theory
Deep neural networks, which mimic the human mind, have established their capability to “examine” from image, audio, and textual content information. Even after being in use for greater than a decade, they are many things that we have not yet realized about deep learning, and how neural networks examine and how they generally work. This will make a way to new principles that are applicable to deep mastering. It shows that after the preliminary phase the deep neural network will “forget” and compress noisy statistics. The data units contain lots of additional facts while preserving the facts that represent the exact information.
To know how exactly deep learning works will evolve in development of new technologies. For example, it can yield insights into most desirable network layout and structure selections, even after offering an extended transparency for protection in regular programs
Deep Convolutional neural networks (CNN's) are utilized in hundreds of layers and 10,000s of nodes. Such network sizes entail formidable challenges in education, working, and storing the networks. Very deep and extensive CNN's might also consequently not be properly suited in running below intense resource constraints as is the case, e.g., in low-electricity embedded and cell systems. This develops a harmonic analysis method to CNN's with the intention of the impact of CNN topology, intensity, and width, on the network’s feature extraction.
Deep Learning is now mainly used in various applications. However, it is regularly criticized for lacking a fundamental theory which can absolutely find a way on how it works.
Ensemble Models in Machine Learning
What is ensembling?
In standard, ensembling is a technique of combining two or more algorithms of same or different sorts known as base learners. This is carried out to make a far better device which incorporates the predictions from all the base learners. It can be understood as a convention room meeting among multiple buyers to decide on whether the price of a product will rise or not.
When you consider that all have an exclusive understanding of the inventory market and for that reason an exceptional mapping feature from the hassle assertion to the favored outcome. Consequently, they're supposed to make varied predictions on the stock cost based totally on their own understandings of the market.
Now we can take all of those predictions into account by making the very final decision. This will make our final selection more relevant, accurate and less possible to be biased. The very last choice would be contrary if this sort of buyers might have made this selection by themselves.
Types of ensembling
Averaging: Assuming the average number of predictions from the models to the predicting
Majority vote: Assuming the maximum prediction votes from the model’s while predicting them by the outcomes of a classification problem.
Weighted average: Here we consider the different weights from multiple models and then we assume the average means of a particular model output.
NEURAL NETWORKS
As we know the concepts of neural networks were around for past many years, but in the recent years the computing power has caught up. Many computational systems like Hadoop’s MapReduce paradigm which doesn’t need a supercomputer to handle the huge calculations of neural networks you can simply spread the process across the clusters.
Neural networks are mostly used to identify the non-linear pattern recognition, as in patterns we cannot find any instantaneous or one-to-one relationship between the input and the output, or the networks become aware of patterns between the inputs and a given output.
Many media reviews describe artificial neural networks as operating like the human mind, but this is a piece of an oversimplification. For one, the difference in scale is a top-notch while neural networks have extended in length, they nevertheless commonly include among some thousand and some million neurons, as compared to the 85 billion or so neurons determined in a regular human brain.
The most important difference is how these neurons are related. Inside the mind, neurons may be connected to many different neurons nearby. In a normal neural community, however, data only flows in one manner. Those neurons are spread across 3 layers:
• The input layer consists of the neurons that can only receive the facts and skip it on. The number of neurons in the input layer must be identical to the variety of capabilities in your data set.
• The output layer consists a number of nodes depending on the type of model you’re constructing. Here, there could be one node for every sort of label you might be making use of, even as in a regression system there'll simply be an unmarried node that puts out a value.
• In between these two layers is where things get more interesting. Here, we have the hidden layer, which additionally includes several neurons. The nodes within the hidden layer practice transformations to the inputs before passing them on. because the community has been trained and those nodes located are extra predictive of the results and are weighted heavily.
Mastering Machine Learning
Artificial intelligence (AI) and machine learning are transforming the global economy, and companies that are quick to adopt these technologies will take $1.2 trillion from those who don’t. Businesses that fail to take advantage of predictive analytics, or don’t have the time or resources – like highly-trained (and expensive) data scientists – will fall behind organizations that embrace AI and machine learning to extract business value from their data.
Enter automated machine learning, a new class of solutions for accelerating and optimizing the predictive analytics process. Incorporating the experience and expertise of top data scientists, automated machine learning automates many of the complex and repetitive tasks required in traditional data science, while providing guardrails to ensure critical steps are not missed. The bottom line: data scientists are more productive and business analysts and other domain experts are transformed into “citizen data scientists” that have the ability to create AI solutions.
As more so-called “automated machine learning” tools are brought to market, often with limited feature sets, there is a need to define the requirements for a true automated machine learning platform. This highlights the 10 capabilities that must be addressed to be considered a complete automated machine learning solution.
1. Preprocessing of Data
Each machine learning algorithm works differently, and has different data requirements. For example, some algorithms need numeric features to be normalized, and some require text processing that splits the text into words and phrases, which can be very complicated for languages like Japanese. Users should expect their automated machine learning platform to know how to best prepare data for every algorithm and following best practices for data partitioning.
2. Feature Engineering
Feature engineering is the process of altering the data to help machine learning algorithms work better, which is often time-consuming and can be expensive. While some feature engineering requires domain knowledge of the data and business rules, most feature engineering is generic. A true automated machine learning platform will engineer new features from existing numeric, categorical, and text features. The system should understand which algorithms benefit from extra feature engineering and which don’t, and only generate features that make sense given the data characteristics.
3. Diverse Algorithms
Every dataset contains unique information that reflects the individual events and characteristics of a business. Due to the variety of situations and conditions represented in the data, one algorithm cannot successfully solve every possible business problem or dataset. Automated machine learning platforms need access to a diverse repository of algorithms to test against the data in order to find the right algorithm to solve the challenge at hand. And, the platform should be updated continually with the most promising new machine learning algorithms, including those from the open source community.
4. Algorithm Selection
Having access to hundreds of algorithms is great, but many organizations don’t have the time to try every algorithm on their data. And some algorithms aren’t suited to their data or data sizes, while others are extremely unlikely to work well on their data altogether. An automated machine learning platform should know which algorithms are right for a business’ data and test the data on only the appropriate algorithms to achieve results faster.
5. Training and Tuning
It’s standard for machine learning software to train an algorithm on the data, but often there is still some hyperparameter tuning required to optimize the algorithm’s performance. In addition, it’s important to understand which features to leave in or out, and which feature selections work best for different models. An effective automated machine learning platform employs smart hyperparameter tuning for each individual model, as well as automatic feature selection, to improve both the speed and accuracy of a model.
6. Ensembling
Teams of algorithms are called “ensembles” or “blenders,” with each algorithm’s strengths balancing out the weaknesses of another. Ensemble models typically outperform individual algorithms because of their diversity. An automated machine learning platform should find the optimal algorithms to blend, include a diverse range of algorithms, and tune the weighting of the algorithms within each blender.
7. Head-to-Head Model Competitions
It’s difficult to know ahead of time which algorithm will perform best in a particular modeling challenge, so it’s necessary to compare the accuracy and speed of different algorithms on the data, regardless of the programming language or machine learning library the algorithms come from. A true automated machine learning platform must build and train dozens of algorithms, comparing the accuracy, speed, and individual predictions of each algorithm and then ranking the algorithms based on the needs of the business.
8. Human-Friendly Insights
Machine learning and AI have made massive strides in predictive power, but often at the price of complexity and interpretability. It’s not enough for a model to score well on accuracy and speed – users must trust the answers. And in some industries, and even some geographies (see the EU’s GDPR), models must comply with regulations and be validated by a compliance team. Automated machine learning should describe model performance in a human-interpretable manner and provide easy-to-understand reasons for individual predictions to help an organization achieve compliance.
9. Easy Deployment
An analytics team can build an impressive predictive model, but it is of little use if the model is too complex for the IT team to reproduce, or if the business lacks the infrastructure to deploy the model to production. Easy, flexible deployment options are a hallmark of a workable automated machine learning solution, including APIs, exportable scoring code, and on-demand predictions that don’t require the intervention of the IT team.
10. Model Monitoring and Management
Even the best models can go “stale” over time as conditions change or new sources of data become available. An ideal automated machine learning solution makes it easy to run a new model competition on the latest data, helping to determine if that model is still the best, or if there is a need to update the model. And as models change, the system should also be able to quickly update the documentation on the model to comply with regulatory requirements.
Businesses that turn to automated machine learning encompassing these features will save time, increase accuracy, and reduce compliance risk when building out their machine learning models – helping them become a truly AI-driven enterprise.
New technology widening gap between the world’s biggest and smallest businesses
Companies investing in robotics, among other digital technologies, are seeing productivity and profits increase, but the cost involved risks creating an even wider gap between the world’s top companies and their smaller rivals, new research shows.
According to a report by the World Economic Forum and based on a survey of more than 16,000 businesses, the bulk of the productivity growth associated with techs such as robotics, AI, and big data analytics is currently being driven by the top 20 percent of firms in each industry.
The researchers warn that without broader implementation of new technology, “an ‘industry inequality’ could emerge, creating a small group of highly productive industry leaders and leaving the rest of the economy behind”, with SMEs in particular at risk.
According to the findings, cognitive technologies, like AI and big data analytics, offer the highest monetary return, equivalent to around $1.90 (£1.40) per employee for every $1 invested. The study shows that, while the return on investment in new technologies is positive overall, the productivity increase is three times higher when technologies are used in combination.
The research also provided some reassurance on how robots will impact on people’s job opportunities. “Contrary to concerns about such new technologies as AI and robotics process automation causing worker displacement, employment levels for our sample of companies were stable,” the report stated.
Machine Learning: What it is and Why it matters
Machine learning is a method of data analysis that automates analytical model building. It is a branch of artificial intelligence based on the idea that systems can learn from data, identify patterns and make decisions with minimal human intervention.
Another recent development was that MIT researchers were working on object recognition through flexible machine learning.
Machine learning is starting to reshape how we live, and it’s time we understood what it is, and why it matters.
What is Machine Learning?
Machine learning is a core sub-area of artificial intelligence; it enables computers to get into a mode of self-learning without being explicitly programmed. When exposed to new data, these computer programs are enabled to learn, grow, change, and develop by themselves.
Machine learning is a method of data analysis that automates analytical model building.” In other words, it allows computers to find insightful information without being programmed where to look for a particular piece of information; instead, it does this by using algorithms that iterative learn from data.
Why Machine Learning?
To better understand the uses of machine learning, consider some instances where machine learning is applied: the self-driving Google car, cyber fraud detection, online recommendation engines-like friend suggestions on Facebook, Netflix showcasing the movies and shows you might like, and “more items to consider” and “get yourself a little something” on Amazon-are all examples of applied machine learning.
All these examples echo the vital role machine learning has begun to take in today’s data-rich world. Machines can aid in filtering useful pieces of information that help in major advancements, and we are already seeing how this technology is being implemented in a wide variety of industries.
Some Machine Learning Algorithms and Processes:
Other tools and processes that pair up with the best algorithms to aid in deriving the most value from big data include:
• Comprehensive data quality and management
• GUI for building models and process flows
• Interactive data exploration and visualization of model results
• Comparisons of different machine learning models to quickly identify the best one
• Automated ensemble model evaluation to identify the best performers
• Easy model deployment so you can get repeatable, reliable results quickly
• Integrated end-to-end platform for the automation of the data-to-decision process
Whether you realize it or not, machine learning is one of the most important technology trends-it underlies so many things we use today without even thinking about them. Speech recognition, Amazon and Netflix recommendations, fraud detection, and financial trading are just a few examples of machine learning commonly in use in today’s data-driven world.
A Closer Look at Three Popular Artificial Intelligence Technologies and How They’re Used
From robotic process automation to machine learning algorithms, many of today’s most influential companies are deploying artificial intelligence (AI) technologies to drive business results. While most decision makers are aware of the business opportunities that emerging technologies present, many are unprepared simply because they fail to understand them.
AI includes a variety of technologies and tools, some that have been around for a long time and others that are relatively new. Nevertheless, one thing is clear: businesses are thinking harder about how to prioritize AI in 2018.
According to International Data Corporation (IDC), the widespread adoption of artificial intelligence will jump from $8.0 billion in 2016 to more than $47 billion in 2020. Here’s a closer look at three popular AI technologies and how innovative companies are using them.
When companies talk about using AI technologies, most are referring to machine learning (ML). The most popular branch of AI computing, ML involves training algorithms to perform tasks by learning from historical data rather than human commands. In other words, computers learn without explicit programming. Small start-ups and major brands use ML to access, organize, and make decisions off data in a more efficient and results-driven way.
At SAP, machine learning is an essential component of a content marketing strategy. The enterprise software company uses ML to analyze content to provide a more tailored experience for their customers. ML algorithms map published articles by themes, helping SAP personalize customer engagement through content.
The goal is to help the audience find more relevant articles based on their unique behaviours and search histories. For SAP, ML-powered technology allows them to go beyond standard recommendation engines with insights that inform targeting and content that engages the right customers with the right creative experience at the right time.
Computer vision is a branch of AI that deals with how computers imitate human sight and the human ability to view and interpret digital images. Through pattern recognition and image processing, computer vision understands the contents of pictures, and it’s having a profound impact on how we experience the world around us.
Amazon uses computer vision technology to improve brick-and-mortar shopping for customers through its Amazon Go experience. With no lines and no checkouts, customers simply use the Amazon Go app to enter the store, choose the items they want, and leave. How? Cameras snap pictures of customers as they shop. Using machine vision, deep learning, and sensor fusion, Amazon keeps track of items in a virtual cart, appropriately charging the right Amazon account.
Vision-guided retail is only the beginning, as computer vision will also likely open doors for smart cities where advanced vision technologies may be able to help reduce the number of collisions and injuries on the road.
AI-driven software, like robotic process automation (RPA), has become a competitive advantage for companies around the world. Digital technologies like RPA improve efficiencies, reduce mistakes, and even disrupt the way companies’ craft customer experiences.
South Africa’s largest bank, Standard Bank, digitized legacy processes through RPA, ML, and cognitive automation, increasing efficiencies in operational, back-office work. As a result, they’ve reduced customer on boarding time from 20 days to 5 minutes!
RPA software gave Standard Bank the flexibility and capability to deal with the challenges of financial services while staying current with other industries. RPA technology reduced mistakes and turned mundane work into something interesting, all while delivering a richer experience for their customers.
Conference Highlights
- Robotic Process Automation (RPA)
- Artificial Neural Networks (ANN) & Chainer
- Natural Language Processing (NLP) and Speech Recognition
- Computer Vision and Image Processing
- Pattern Recognition
- Deep Learning Frameworks
- Dimensionality Reduction
- Model Selection and Boosting
- Big Data, Data Science and Data Mining
- Object Detection with Digits
- Facial Expression and Emotion Detection
- Cloud Computing
- Deep Learning
- Machine Learning
- The role of AI & Machine Learning in Medical Science
- Predictive Analytics
- Big Data Analytics
- Artificial Intelligence
- Internet of Things (IoT)
To share your views and research, please click here to register for the Conference.
To Collaborate Scientific Professionals around the World
| Conference Date | August 30-31, 2018 | ||
| Sponsors & Exhibitors |
|
||
| Speaker Opportunity Closed | Day 1 | Day 2 | |
| Poster Opportunity Closed | Click Here to View | ||




























Useful Links
Special Issues
All accepted abstracts will be published in respective Our International Journals.
- Journal of Information Technology & Software Engineering
- Journal of Computer Science & Systems Biology
- Journal of Proteomics & Bioinformatics
Abstracts will be provided with Digital Object Identifier by









